Zig Cookbook


![]()
![]()
![]()
Zig cookbook is a collection of simple Zig programs that demonstrate good practices to accomplish common programming tasks.
- Main branch tracks Zig 0.14.0 and master, and are tested on Linux and macOS via GitHub actions.
- Earlier Zig support could be found in other branches.
How to use
The website is generated by mdbook, mdbook serve will start a server at http://localhost:3000 for preview.
Each recipe is accompanied by an illustrative example named after its corresponding sequence number. These examples can be executed using the command zig build run-{chapter-num}-{sequence-num}, or zig build run-all to execute all.
Note
Some recipes may depend on system libraries
- Use
make install-depsto install client libraries, anddocker-compose up -dto start required databases.
Contributing
This cookbook is a work in progress, and we welcome contributions from the community. If you have a favorite recipe that you'd like to share, please submit a pull request.
Acknowledgment
When working on zig-cookbook, we benefit a lot from several similar projects, thanks for their awesome work.
Star History
License
The markdown files are licensed under CC BY-NC-ND 4.0 DEED, and zig files are under MIT.
Read file line by line
There is a Reader type in Zig, which provides various methods to read file, such as readAll, readInt. Here we will use streamUntilDelimiter to split lines.
const std = @import("std");
const fs = std.fs;
const print = std.debug.print;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
const file = try fs.cwd().openFile("tests/zig-zen.txt", .{});
defer file.close();
// Wrap the file reader in a buffered reader.
// Since it's usually faster to read a bunch of bytes at once.
var buf_reader = std.io.bufferedReader(file.reader());
const reader = buf_reader.reader();
var line = std.ArrayList(u8).init(allocator);
defer line.deinit();
const writer = line.writer();
var line_no: usize = 0;
while (reader.streamUntilDelimiter(writer, '\n', null)) {
// Clear the line so we can reuse it.
defer line.clearRetainingCapacity();
line_no += 1;
print("{d}--{s}\n", .{ line_no, line.items });
} else |err| switch (err) {
error.EndOfStream => { // end of file
if (line.items.len > 0) {
line_no += 1;
print("{d}--{s}\n", .{ line_no, line.items });
}
},
else => return err, // Propagate error
}
print("Total lines: {d}\n", .{line_no});
}
Mmap file
Creates a memory map of a file using mmap and simulates some non-sequential reads from the file. Using a memory map means you just index into a slice rather than having to deal with seek to navigate a file.
const std = @import("std");
const fs = std.fs;
const print = std.debug.print;
const filename = "/tmp/zig-cookbook-01-02.txt";
pub fn main() !void {
if (.windows == @import("builtin").os.tag) {
std.debug.print("MMap is not supported in Windows\n", .{});
return;
}
const file = try fs.cwd().createFile(filename, .{
.read = true,
.truncate = true,
.exclusive = false, // Set to true will ensure this file is created by us
});
defer file.close();
const content_to_write = "hello zig cookbook";
// Before mmap, we need to ensure file isn't empty
try file.setEndPos(content_to_write.len);
const md = try file.metadata();
try std.testing.expectEqual(md.size(), content_to_write.len);
const ptr = try std.posix.mmap(
null,
content_to_write.len,
std.posix.PROT.READ | std.posix.PROT.WRITE,
.{ .TYPE = .SHARED },
file.handle,
0,
);
defer std.posix.munmap(ptr);
// Write file via mmap
std.mem.copyForwards(u8, ptr, content_to_write);
// Read file via mmap
try std.testing.expectEqualStrings(content_to_write, ptr);
}
Find files that have been modified in the last 24 hours
Gets the current working directory by calling fs.cwd(), and then iterates files using walk(), which will recursively iterate entries in the directory.
For each entry, we check if it's a file, and use statFile() to retrieve the file's metadata.
//! Find files that have been modified in the last 24 hours
const std = @import("std");
const builtin = @import("builtin");
const fs = std.fs;
const print = std.debug.print;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var iter_dir = try fs.cwd().openDir("src", .{ .iterate = true });
defer iter_dir.close();
var walker = try iter_dir.walk(allocator);
defer walker.deinit();
const now = std.time.nanoTimestamp();
while (try walker.next()) |entry| {
if (entry.kind != .file) {
continue;
}
const stat = try iter_dir.statFile(entry.path);
const last_modified = stat.mtime;
const duration = now - last_modified;
if (duration < std.time.ns_per_hour * 24) {
print("Last modified: {d} seconds ago, size:{d} bytes, filename: {s}\n", .{
@divTrunc(duration, std.time.ns_per_s),
stat.size,
entry.path,
});
}
}
}
Check file existence
In this example, access is utilized to verify file existence; however, for it to function correctly, one must specifically check for the FileNotFound error type.
//! Test file/directory existence
const std = @import("std");
const fs = std.fs;
pub fn main() !void {
const filename = "build.zig";
var found = true;
fs.cwd().access(filename, .{}) catch |e| switch (e) {
error.FileNotFound => found = false,
else => return e,
};
std.debug.assert(found);
}
However, there is a gotcha described in its documentation:
Be careful of Time-Of-Check-Time-Of-Use race conditions when using this function. For example, instead of testing if a file exists and then opening it, just open it and handle the error for file not found.
Iterate directory
There is a convenient method walk for this purpose, it will walk the directory iteratively.
const std = @import("std");
const fs = std.fs;
const print = std.debug.print;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer if (gpa.deinit() != .ok) @panic("leak");
const allocator = gpa.allocator();
// In order to walk the directry, `iterate` must be set to true.
var dir = try fs.cwd().openDir("zig-out", .{ .iterate = true });
defer dir.close();
var walker = try dir.walk(allocator);
defer walker.deinit();
while (try walker.next()) |entry| {
print("path: {s}, basename:{s}, type:{s}\n", .{
entry.path,
entry.basename,
@tagName(entry.kind),
});
}
}
The order of returned file system entries is undefined, if there are any requirements for the order in which to return the entries, such as alphabetical or chronological, sort them accordingly. Otherwise, leave them in their original, unsorted order.
Calculate SHA-256 digest of a file
There are many crypto algorithm implementations in std, sha256, md5 are supported out of box.
const std = @import("std");
const fs = std.fs;
const Sha256 = std.crypto.hash.sha2.Sha256;
// In real world, this may set to page_size, usually it's 4096.
const BUF_SIZE = 16;
fn sha256_digest(
file: fs.File,
) ![Sha256.digest_length]u8 {
var sha256 = Sha256.init(.{});
const rdr = file.reader();
var buf: [BUF_SIZE]u8 = undefined;
var n = try rdr.read(&buf);
while (n != 0) {
sha256.update(buf[0..n]);
n = try rdr.read(&buf);
}
return sha256.finalResult();
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
const file = try fs.cwd().openFile("tests/zig-zen.txt", .{});
defer file.close();
const digest = try sha256_digest(file);
const hex_digest = try std.fmt.allocPrint(
allocator,
"{s}",
.{std.fmt.fmtSliceHexLower(&digest)},
);
defer allocator.free(hex_digest);
try std.testing.expectEqualStrings(
"2210e9263ece534df0beff39ec06850d127dc60aa17bbc7769c5dc2ea5f3e342",
hex_digest,
);
}
Salt and hash a password with PBKDF2
Uses std.crypto.pwhash.pbkdf2 to hash a salted password. The salt is generated
using std.rand.DefaultPrng, which fills the salt byte array with generated
random numbers.
const std = @import("std");
const print = std.debug.print;
const crypto = std.crypto;
const HmacSha256 = crypto.auth.hmac.sha2.HmacSha256;
pub fn main() !void {
const salt = [_]u8{ 'a', 'b', 'c' };
const password = "Guess Me If You Can!";
const rounds = 1_000;
// Usually 16 or 32 bytes
var derived_key: [16]u8 = undefined;
try crypto.pwhash.pbkdf2(&derived_key, password, &salt, rounds, HmacSha256);
try std.testing.expectEqualSlices(
u8,
&[_]u8{
44,
184,
223,
181,
238,
128,
211,
50,
149,
114,
26,
86,
225,
172,
116,
81,
},
&derived_key,
);
}
Measure the elapsed time between two code sections
Instant represents a timestamp with respect to the currently executing program that ticks while the program is suspended and can be used to record elapsed time.
Calling std.time.Instant.since returns a u64 representing nanoseconds elapsed.
This is such a common task, that there is a Timer for convenience.
const std = @import("std");
const time = std.time;
const Instant = time.Instant;
const Timer = time.Timer;
const print = std.debug.print;
fn expensive_function() void {
// sleep 500ms
time.sleep(time.ns_per_ms * 500);
}
pub fn main() !void {
// Method 1: Instant
const start = try Instant.now();
expensive_function();
const end = try Instant.now();
const elapsed1: f64 = @floatFromInt(end.since(start));
print("Time elapsed is: {d:.3}ms\n", .{
elapsed1 / time.ns_per_ms,
});
// Method 2: Timer
var timer = try Timer.start();
expensive_function();
const elapsed2: f64 = @floatFromInt(timer.read());
print("Time elapsed is: {d:.3}ms\n", .{
elapsed2 / time.ns_per_ms,
});
}
Listen on unused port TCP/IP
In this example, the port is displayed on the console, and the program will
listen until a request is made. Ip4Address assigns a random port when
setting port to 0.
//! Start a TCP server at an unused port.
//!
//! Test with
//! echo "hello zig" | nc localhost <port>
const std = @import("std");
const net = std.net;
const print = std.debug.print;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
const loopback = try net.Ip4Address.parse("127.0.0.1", 0);
const localhost = net.Address{ .in = loopback };
var server = try localhost.listen(.{
.reuse_address = true,
});
defer server.deinit();
const addr = server.listen_address;
print("Listening on {}, access this port to end the program\n", .{addr.getPort()});
var client = try server.accept();
defer client.stream.close();
print("Connection received! {} is sending data.\n", .{client.address});
const message = try client.stream.reader().readAllAlloc(allocator, 1024);
defer allocator.free(message);
print("{} says {s}\n", .{ client.address, message });
}
When start starts up, try test like this:
echo "hello zig" | nc localhost <port>
By default, the program listens with IPv4. If you want IPv6, use ::1
instead of 127.0.0.1, replace net.Ip4Address.parse by
net.Ip6Address.parse and the field .in in the creation of the
net.Address with .in6.
(And connect to something like ip6-localhost, depending on the way
your machine is set up.)
The next section will show how to connect to this server using Zig code.
TCP Client
In this example, we demonstrate creation of a TCP client to connect to the server from the previous section.
You can run it using zig build run-04-02 -- <port>.
const std = @import("std");
const net = std.net;
const print = std.debug.print;
pub fn main() !void {
var args = std.process.args();
// The first (0 index) Argument is the path to the program.
_ = args.skip();
const port_value = args.next() orelse {
print("expect port as command line argument\n", .{});
return error.NoPort;
};
const port = try std.fmt.parseInt(u16, port_value, 10);
const peer = try net.Address.parseIp4("127.0.0.1", port);
// Connect to peer
const stream = try net.tcpConnectToAddress(peer);
defer stream.close();
print("Connecting to {}\n", .{peer});
// Sending data to peer
const data = "hello zig";
var writer = stream.writer();
const size = try writer.write(data);
print("Sending '{s}' to peer, total written: {d} bytes\n", .{ data, size });
// Or just using `writer.writeAll`
// try writer.writeAll("hello zig");
}
By default, the program connects with IPv4. If you want IPv6, use
::1 instead of 127.0.0.1, replace net.Address.parseIp4 by
net.Address.parseIp6.
UDP Echo
Similar to the TCP server example, this program will listen on the specified IP address and port, but for UDP datagrams this time. If data is received, it will be echoed back to the sender's address.
Although std.net is mostly focused on abstractions for TCP (so far), we can still
make use of socket programming to communicate via UDP.
//! Start a UDP echo on an unused port.
//!
//! Test with
//! echo "hello zig" | nc -u localhost <port>
const std = @import("std");
const net = std.net;
const posix = std.posix;
const print = std.debug.print;
pub fn main() !void {
// adjust the ip/port here as needed
const addr = try net.Address.parseIp("127.0.0.1", 32100);
// get a socket and set domain, type and protocol flags
const sock = try posix.socket(
posix.AF.INET,
posix.SOCK.DGRAM,
posix.IPPROTO.UDP,
);
// for completeness, we defer closing the socket. In practice, if this is
// a one-shot program, we could omit this and let the OS do the cleanup
defer posix.close(sock);
try posix.bind(sock, &addr.any, addr.getOsSockLen());
var other_addr: posix.sockaddr = undefined;
var other_addrlen: posix.socklen_t = @sizeOf(posix.sockaddr);
var buf: [1024]u8 = undefined;
print("Listen on {any}...\n", .{addr});
// we did not set the NONBLOCK flag (socket type flag),
// so the program will wait until data is received
const n_recv = try posix.recvfrom(
sock,
buf[0..],
0,
&other_addr,
&other_addrlen,
);
print(
"received {d} byte(s) from {any};\n string: {s}\n",
.{ n_recv, other_addr, buf[0..n_recv] },
);
// we could extract the source address of the received data by
// parsing the other_addr.data field
const n_sent = try posix.sendto(
sock,
buf[0..n_recv],
0,
&other_addr,
other_addrlen,
);
print("echoed {d} byte(s) back\n", .{n_sent});
}
After starting the program, test as follows with nc, using the -u flag for UDP:
echo "hello zig" | nc -u localhost <port>
GET
Parses the supplied URL and makes a synchronous HTTP GET request
with request. Prints obtained Response status and headers.
Note: Since HTTP support is in early stage, it's recommended to use libcurl for any complex task. And when the buffer is not enough, it will return
error.HttpHeadersOverSize
const std = @import("std");
const print = std.debug.print;
const http = std.http;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var client = http.Client{ .allocator = allocator };
defer client.deinit();
const uri = try std.Uri.parse("http://httpbin.org/headers");
const buf = try allocator.alloc(u8, 1024 * 8);
defer allocator.free(buf);
var req = try client.open(.GET, uri, .{
.server_header_buffer = buf,
});
defer req.deinit();
try req.send();
try req.finish();
try req.wait();
var iter = req.response.iterateHeaders();
while (iter.next()) |header| {
std.debug.print("Name:{s}, Value:{s}\n", .{ header.name, header.value });
}
try std.testing.expectEqual(req.response.status, .ok);
var rdr = req.reader();
const body = try rdr.readAllAlloc(allocator, 1024 * 1024 * 4);
defer allocator.free(body);
print("Body:\n{s}\n", .{body});
}
POST
Parses the supplied URL and makes a synchronous HTTP POST request
with request. Prints obtained Response status, and data received from server.
Note: Since HTTP support is in early stage, it's recommended to use libcurl for any complex task.
const std = @import("std");
const print = std.debug.print;
const http = std.http;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var client = http.Client{ .allocator = allocator };
defer client.deinit();
const uri = try std.Uri.parse("https://httpbin.org/anything");
const payload =
\\ {
\\ "name": "zig-cookbook",
\\ "author": "John"
\\ }
;
var buf: [1024]u8 = undefined;
var req = try client.open(.POST, uri, .{ .server_header_buffer = &buf });
defer req.deinit();
req.transfer_encoding = .{ .content_length = payload.len };
try req.send();
var wtr = req.writer();
try wtr.writeAll(payload);
try req.finish();
try req.wait();
// Occasionally, httpbin might time out, so we disregard cases
// where the response status is not okay.
if (req.response.status != .ok) {
return;
}
var rdr = req.reader();
const body = try rdr.readAllAlloc(allocator, 1024 * 1024 * 4);
defer allocator.free(body);
print("Body:\n{s}\n", .{body});
}
http.Server - std
A basic implementation of http.Server has been introduced since Zig 0.12.0.
For each connection we spawn a new thread to handle it, in accept it will:
- First it use
deferto ensure the connection is closed when returned. - Then init a HTTP server to begin parse request
- For each request, we first check if it could upgrade to WebSocket.
- If it succeeds, call
serveWebSocketelse callserverHTTP
- If it succeeds, call
const std = @import("std");
const log = std.log;
const WebSocket = std.http.WebSocket;
const Request = std.http.Server.Request;
const Connection = std.net.Server.Connection;
const MAX_BUF = 1024;
pub fn main() !void {
const addr = try std.net.Address.parseIp("127.0.0.1", 8080);
var server = try std.net.Address.listen(addr, .{ .reuse_address = true });
defer server.deinit();
log.info("Start HTTP server at {any}", .{addr});
while (true) {
const conn = server.accept() catch |err| {
log.err("failed to accept connection: {s}", .{@errorName(err)});
continue;
};
_ = std.Thread.spawn(.{}, accept, .{conn}) catch |err| {
log.err("unable to spawn connection thread: {s}", .{@errorName(err)});
conn.stream.close();
continue;
};
}
}
fn accept(conn: Connection) !void {
defer conn.stream.close();
log.info("Got new client({any})!", .{conn.address});
var read_buffer: [MAX_BUF]u8 = undefined;
var server = std.http.Server.init(conn, &read_buffer);
while (server.state == .ready) {
var request = server.receiveHead() catch |err| switch (err) {
error.HttpConnectionClosing => return,
else => return err,
};
var ws: WebSocket = undefined;
var send_buf: [MAX_BUF]u8 = undefined;
var recv_buf: [MAX_BUF]u8 align(4) = undefined;
if (try ws.init(&request, &send_buf, &recv_buf)) {
// Upgrade to web socket successfully.
serveWebSocket(&ws) catch |err| switch (err) {
error.ConnectionClose => {
log.info("Client({any}) closed!", .{conn.address});
break;
},
else => return err,
};
} else {
try serveHTTP(&request);
}
}
}
fn serveHTTP(request: *Request) !void {
try request.respond(
"Hello World from Zig HTTP server",
.{
.extra_headers = &.{
.{ .name = "custom header", .value = "custom value" },
},
},
);
}
fn serveWebSocket(ws: *WebSocket) !void {
try ws.writeMessage("Message from zig", .text);
while (true) {
const msg = try ws.readSmallMessage();
try ws.writeMessage(msg.data, msg.opcode);
}
}
Test
For HTTP, we could use curl:
curl -v localhost:8080
It will output:
< HTTP/1.1 200 OK
< content-length: 32
< custom header: custom value
<
Hello World from Zig HTTP server
For WebSocket, we could use console in your browser's Developer Tools:
var webSocket = new WebSocket('ws://localhost:8080');
webSocket.onmessage = function(data) { console.log(data); }
Then we could send message like this:
webSocket.send('abc')
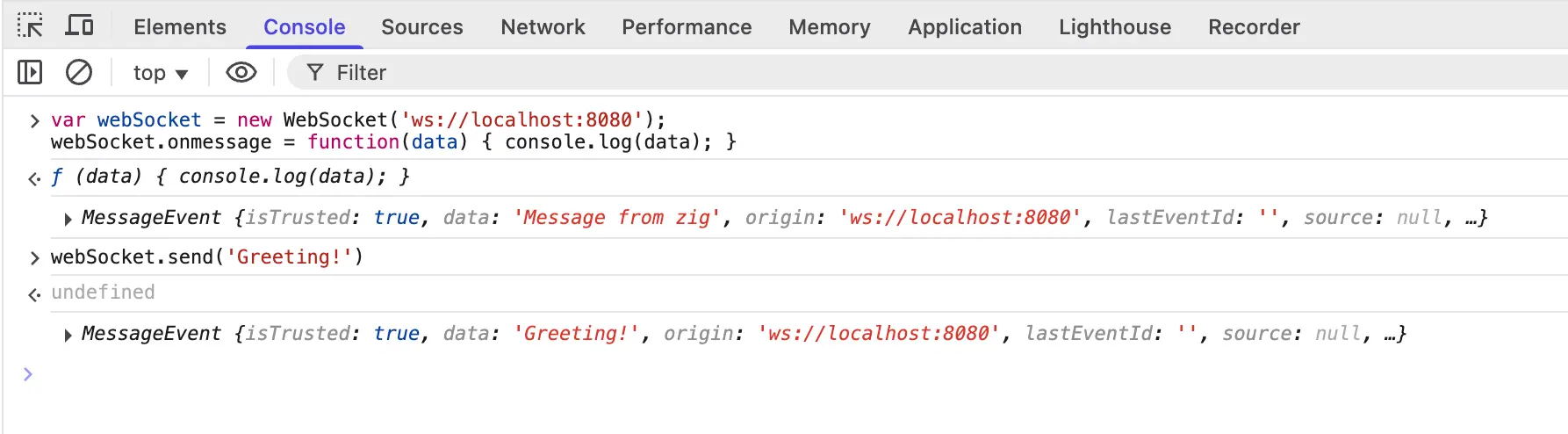
See Writing WebSocket client applications - Web APIs | MDN for details.
Note
The std implementation exhibits extremely poor performance. If you're planning beyond basic experimentation, consider utilizing alternative libraries such as:
Generate random numbers
Generates random numbers with the help of a thread-local, cryptographically secure pseudo random number generator std.crypto.random.
const std = @import("std");
const print = std.debug.print;
pub fn main() !void {
const rand = std.crypto.random;
print("Random u8: {}\n", .{rand.int(u8)});
print("Random u8 less than 10: {}\n", .{rand.uintLessThan(u8, 10)});
print("Random u16: {}\n", .{rand.int(u16)});
print("Random u32: {}\n", .{rand.int(u32)});
print("Random i32: {}\n", .{rand.int(i32)});
print("Random float: {d}\n", .{rand.float(f64)});
var i: usize = 0;
while (i < 9) {
print("Random enum: {}\n", .{rand.enumValue(enum { red, green, blue })});
i += 1;
}
}
Spawn a short-lived thread
The example uses std.Thread for concurrent and parallel programming.
std.Thread.spawn spawns a new thread to calculate the result.
This example splits the array in half and performs the work in separate threads.
Note: In order to ensure
t1thread is completed when spawnt2fails, wedefer t1.join()immediately after spawnt1.
const std = @import("std");
pub fn main() !void {
var arr = [_]i32{ 1, 25, -4, 10, 100, 200, -100, -200 };
var max_value: i32 = undefined;
try findMax(&max_value, &arr);
try std.testing.expectEqual(max_value, 200);
}
fn findMax(max_value: *i32, values: []i32) !void {
const THRESHOLD: usize = 2;
if (values.len <= THRESHOLD) {
var res = values[0];
for (values) |it| {
res = @max(res, it);
}
max_value.* = res;
return;
}
const mid = values.len / 2;
const left = values[0..mid];
const right = values[mid..];
var left_max: i32 = undefined;
var right_max: i32 = undefined;
// This block is necessary to ensure that all threads are joined before proceeding.
{
const t1 = try std.Thread.spawn(.{}, findMax, .{ &left_max, left });
defer t1.join();
const t2 = try std.Thread.spawn(.{}, findMax, .{ &right_max, right });
defer t2.join();
}
max_value.* = @max(left_max, right_max);
}
Share data between two threads
When we want to mutate data shared between threads, Mutex(Mutually exclusive flag) must be used to synchronize threads, otherwise the result maybe unexpected.
const std = @import("std");
const Thread = std.Thread;
const Mutex = Thread.Mutex;
const SharedData = struct {
mutex: Mutex,
value: i32,
pub fn updateValue(self: *SharedData, increment: i32) void {
// Use `tryLock` if you don't want to block
self.mutex.lock();
defer self.mutex.unlock();
for (0..10000) |_| {
self.value += increment;
}
}
};
pub fn main() !void {
var shared_data = SharedData{ .mutex = Mutex{}, .value = 0 };
// This block is necessary to ensure that all threads are joined before proceeding.
{
const t1 = try Thread.spawn(.{}, SharedData.updateValue, .{ &shared_data, 1 });
defer t1.join();
const t2 = try Thread.spawn(.{}, SharedData.updateValue, .{ &shared_data, 2 });
defer t2.join();
}
try std.testing.expectEqual(shared_data.value, 30_000);
}
If we remove Mutex protection, the result will most like be less than 30,000.
Thread pool
Thread pools address two different problems:
- They usually provide improved performance when executing large numbers of asynchronous tasks, due to reduced per-task invocation overhead, and
- They provide a means of bounding and managing the resources, including threads, consumed when executing a collection of tasks.
In this example, we spawn 10 tasks into thread pool, and use WaitGroup to wait for them to finish.
const std = @import("std");
const print = std.debug.print;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer if (gpa.deinit() != .ok) @panic("leak");
const allocator = gpa.allocator();
var pool: std.Thread.Pool = undefined;
try pool.init(.{
.allocator = allocator,
.n_jobs = 4,
});
defer pool.deinit();
var wg: std.Thread.WaitGroup = .{};
for (0..10) |i| {
pool.spawnWg(&wg, struct {
fn run(id: usize) void {
print("I'm from {d}\n", .{id});
}
}.run, .{i});
}
wg.wait();
print("All threads exit.\n", .{});
}
Run Once
std.once ensures a function executes exactly one time, regardless of how many threads attempt to call it or how many times it's invoked. This thread-safe initialization is particularly useful for singleton patterns and one-time setup operations.
const std = @import("std");
var n: u8 = 0;
fn incr() void {
n = n + 1;
}
var once_incr = std.once(incr);
fn onceIncr() void {
// The invocations of `call` are thread-safe.
once_incr.call();
once_incr.call();
}
pub fn main() !void {
{
const t1 = try std.Thread.spawn(.{}, onceIncr, .{});
defer t1.join();
const t2 = try std.Thread.spawn(.{}, onceIncr, .{});
defer t2.join();
}
try std.testing.expectEqual(1, n);
}
Check number of logical cpu cores
Shows the number of logical CPU cores in the current machine using std.Thread.getCpuCount.
const std = @import("std");
const print = std.debug.print;
pub fn main() !void {
print("Number of logical cores is {}\n", .{try std.Thread.getCpuCount()});
}
External Command
Run an external command via std.process.Child, and collect output into ArrayList via pipe.
const std = @import("std");
const print = std.debug.print;
const Child = std.process.Child;
const ArrayList = std.ArrayList;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer if (gpa.deinit() != .ok) @panic("leak");
const allocator = gpa.allocator();
const argv = [_][]const u8{
"echo",
"-n",
"hello",
"world",
};
// By default, child will inherit stdout & stderr from its parents,
// this usually means that child's output will be printed to terminal.
// Here we change them to pipe and collect into `ArrayList`.
var child = Child.init(&argv, allocator);
child.stdout_behavior = .Pipe;
child.stderr_behavior = .Pipe;
var stdout: std.ArrayListUnmanaged(u8) = .empty;
defer stdout.deinit(allocator);
var stderr: std.ArrayListUnmanaged(u8) = .empty;
defer stderr.deinit(allocator);
try child.spawn();
try child.collectOutput(allocator, &stdout, &stderr, 1024);
const term = try child.wait();
try std.testing.expectEqual(term.Exited, 0);
try std.testing.expectEqualStrings("hello world", stdout.items);
try std.testing.expectEqualStrings("", stderr.items);
}
Parse a version string.
Constructs a std.SemanticVersion from a string literal using SemanticVersion.parse.
const std = @import("std");
const assert = std.debug.assert;
pub fn main() !void {
const version = try std.SemanticVersion.parse("0.2.6");
assert(version.order(.{
.major = 0,
.minor = 2,
.patch = 6,
.pre = null,
.build = null,
}) == .eq);
}
Serialize and deserialize JSON
The std.json provides a set of functions such as stringify and stringifyAlloc for serializing JSON.
Additionally, we can use parseFromSlice function to parse a []u8 of JSON.
The example below shows a []u8 of JSON being parsed. Compare each member one by one.
Then, we modify the verified field to false and serialize it back into a JSON string.
const std = @import("std");
const json = std.json;
const testing = std.testing;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
// Deserialize JSON
const json_str =
\\{
\\ "userid": 103609,
\\ "verified": true,
\\ "access_privileges": [
\\ "user",
\\ "admin"
\\ ]
\\}
;
const T = struct { userid: i32, verified: bool, access_privileges: [][]u8 };
const parsed = try json.parseFromSlice(T, allocator, json_str, .{});
defer parsed.deinit();
var value = parsed.value;
try testing.expect(value.userid == 103609);
try testing.expect(value.verified);
try testing.expectEqualStrings("user", value.access_privileges[0]);
try testing.expectEqualStrings("admin", value.access_privileges[1]);
// Serialize JSON
value.verified = false;
const new_json_str = try json.stringifyAlloc(allocator, value, .{ .whitespace = .indent_2 });
defer allocator.free(new_json_str);
try testing.expectEqualStrings(
\\{
\\ "userid": 103609,
\\ "verified": false,
\\ "access_privileges": [
\\ "user",
\\ "admin"
\\ ]
\\}
,
new_json_str,
);
}
Serialize and deserialize Zon
ZON ("Zig Object Notation") is a textual file format. Outside of nan and inf literals, ZON's grammar is a subset of Zig's.
Supported Zig primitives:
- boolean literals
- number literals (including
nanandinf) - character literals
- enum literals
nullliterals- string literals
- multiline string literals
Supported Zig container types:
- anonymous struct literals
- anonymous tuple literals
const std = @import("std");
const zon = std.zon;
const Allocator = std.mem.Allocator;
const Student = struct {
name: []const u8,
age: u16,
favourites: []const []const u8,
fn deinit(self: *Student, allocator: Allocator) void {
allocator.free(self.name);
for (self.favourites) |item| {
allocator.free(item);
}
allocator.free(self.favourites);
}
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer if (gpa.deinit() != .ok) @panic("leak");
const allocator = gpa.allocator();
const source = Student{
.name = "John",
.age = 20,
.favourites = &.{ "swimming", "running" },
};
var dst = std.ArrayList(u8).init(allocator);
defer dst.deinit();
try zon.stringify.serialize(source, .{}, dst.writer());
const expected =
\\.{
\\ .name = "John",
\\ .age = 20,
\\ .favourites = .{ "swimming", "running" },
\\}
;
try std.testing.expectEqualStrings(expected, dst.items);
// Make it 0-sentinel
try dst.append(0);
const input = dst.items[0 .. dst.items.len - 1 :0];
var status: zon.parse.Status = .{};
defer status.deinit(allocator);
var parsed = zon.parse.fromSlice(
Student,
allocator,
input,
&status,
.{ .free_on_error = true },
) catch |err| {
std.debug.print("Parse status: {any}\n", .{status});
return err;
};
defer parsed.deinit(allocator);
try std.testing.expectEqualDeep(source, parsed);
}
Encode and decode base64
Encodes a byte slice into base64 string using std.base64.standard encode
and decodes it with standard decode.
const std = @import("std");
const zon = std.zon;
const Allocator = std.mem.Allocator;
const Student = struct {
name: []const u8,
age: u16,
favourites: []const []const u8,
fn deinit(self: *Student, allocator: Allocator) void {
allocator.free(self.name);
for (self.favourites) |item| {
allocator.free(item);
}
allocator.free(self.favourites);
}
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer if (gpa.deinit() != .ok) @panic("leak");
const allocator = gpa.allocator();
const source = Student{
.name = "John",
.age = 20,
.favourites = &.{ "swimming", "running" },
};
var dst = std.ArrayList(u8).init(allocator);
defer dst.deinit();
try zon.stringify.serialize(source, .{}, dst.writer());
const expected =
\\.{
\\ .name = "John",
\\ .age = 20,
\\ .favourites = .{ "swimming", "running" },
\\}
;
try std.testing.expectEqualStrings(expected, dst.items);
// Make it 0-sentinel
try dst.append(0);
const input = dst.items[0 .. dst.items.len - 1 :0];
var status: zon.parse.Status = .{};
defer status.deinit(allocator);
var parsed = zon.parse.fromSlice(
Student,
allocator,
input,
&status,
.{ .free_on_error = true },
) catch |err| {
std.debug.print("Parse status: {any}\n", .{status});
return err;
};
defer parsed.deinit(allocator);
try std.testing.expectEqualDeep(source, parsed);
}
Creating and adding complex numbers
Creates complex numbers of type std.math.Complex. Both the real and
imaginary part of the complex number must be of the same type.
Performing mathematical operations on complex numbers is the same as on built in types: the numbers in question must be of the same type (i.e. floats or integers).
const std = @import("std");
const print = std.debug.print;
const expectEqual = std.testing.expectEqual;
const Complex = std.math.Complex;
pub fn main() !void {
const complex_integer = Complex(i32).init(10, 20);
const complex_integer2 = Complex(i32).init(5, 17);
const complex_float = Complex(f32).init(10.1, 20.1);
print("Complex integer: {}\n", .{complex_integer});
print("Complex float: {}\n", .{complex_float});
const sum = complex_integer.add(complex_integer2);
try expectEqual(sum, Complex(i32).init(15, 37));
}
Bitfield
The fields of a packed struct are always laid out in memory in the order they are written, with no padding, so they are very nice to represent a bitfield.
Boolean values are represented as 1 bit in a packed struct, Zig also has arbitrary bit-width integers, like u28, u1 and so on.
const std = @import("std");
const print = std.debug.print;
const ColorFlags = packed struct(u32) {
red: bool = false,
green: bool = false,
blue: bool = false,
_padding: u29 = 0,
};
pub fn main() !void {
const tom: ColorFlags = @bitCast(@as(u32, 0xFF));
if (tom.red) {
print("Tom likes red.\n", .{});
}
if (tom.red and tom.green) {
print("Tom likes red and green.\n", .{});
}
const jerry: ColorFlags = @bitCast(@as(u32, 0x01));
if (jerry.red) {
print("Jerry likes red.\n", .{});
}
if (jerry.red and !jerry.green) {
print("Jerry likes red, not green.\n", .{});
}
}
Reference
- Packed structs in Zig make bit/flag sets trivial | Hexops' devlog
- A Better Way to Implement Bit Fields
Singly Linked List
Singly linked list contains nodes linked together. The list contains:
head, head of the list, used for traversal.tail, tail of the list, used for fast add.len, length of the list
Operations that can be performed on singly linked lists include:
- Insertion O(1)
- Deletion O(n), which is the most complex since it needs to maintain head/tail pointer.
- Traversal O(n)
const std = @import("std");
const Allocator = std.mem.Allocator;
fn LinkedList(comptime T: type) type {
return struct {
const Node = struct {
data: T,
next: ?*Node = null,
};
const Self = @This();
head: ?*Node = null,
tail: ?*Node = null,
len: usize = 0,
allocator: Allocator,
fn init(allocator: Allocator) Self {
return .{ .allocator = allocator };
}
fn add(self: *Self, value: T) !void {
const node = try self.allocator.create(Node);
node.* = .{ .data = value };
if (self.tail) |*tail| {
tail.*.next = node;
tail.* = node;
} else {
self.head = node;
self.tail = node;
}
self.len += 1;
}
fn remove(self: *Self, value: T) bool {
if (self.head == null) {
return false;
}
// In this loop, we are trying to find the node that contains the value.
// We need to keep track of the previous node to update the tail pointer if necessary.
var current = self.head;
var previous: ?*Node = null;
while (current) |cur| : (current = cur.next) {
if (cur.data == value) {
// If the current node is the head, point head to the next node.
if (self.head.? == cur) {
self.head = cur.next;
}
// If the current node is the tail, point tail to its previous node.
if (self.tail.? == cur) {
self.tail = previous;
}
// Skip the current node and update the previous node to point to the next node.
if (previous) |*prev| {
prev.*.next = cur.next;
}
self.allocator.destroy(cur);
self.len -= 1;
return true;
}
previous = cur;
}
return false;
}
fn search(self: *Self, value: T) bool {
var head: ?*Node = self.head;
while (head) |h| : (head = h.next) {
if (h.data == value) {
return true;
}
}
return false;
}
fn visit(self: *Self, visitor: *const fn (i: usize, v: T) anyerror!void) !usize {
var head = self.head;
var i: usize = 0;
while (head) |n| : (i += 1) {
try visitor(i, n.data);
head = n.next;
}
return i;
}
fn deinit(self: *Self) void {
var current = self.head;
while (current) |n| {
const next = n.next;
self.allocator.destroy(n);
current = next;
}
self.head = null;
self.tail = null;
}
};
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var lst = LinkedList(u32).init(allocator);
defer lst.deinit();
const values = [_]u32{ 32, 20, 21 };
for (values) |v| {
try lst.add(v);
}
try std.testing.expectEqual(lst.len, values.len);
try std.testing.expectEqual(
try lst.visit(struct {
fn visitor(i: usize, v: u32) !void {
try std.testing.expectEqual(values[i], v);
}
}.visitor),
3,
);
try std.testing.expect(lst.search(20));
// Test delete head
try std.testing.expect(lst.remove(32));
try std.testing.expectEqual(
try lst.visit(struct {
fn visitor(i: usize, v: u32) !void {
try std.testing.expectEqual(([_]u32{ 20, 21 })[i], v);
}
}.visitor),
2,
);
// Test delete tail
try std.testing.expect(lst.remove(21));
try std.testing.expectEqual(
try lst.visit(struct {
fn visitor(i: usize, v: u32) !void {
try std.testing.expectEqual(([_]u32{20})[i], v);
}
}.visitor),
1,
);
// Test delete head and tail at the same time
try std.testing.expect(lst.remove(20));
try std.testing.expectEqual(
try lst.visit(struct {
fn visitor(_: usize, _: u32) !void {
unreachable;
}
}.visitor),
0,
);
try std.testing.expectEqual(lst.len, 0);
}
Doubly Linked List
A doubly linked list contains nodes that are linked together in both directions, allowing for more efficient operations in some scenarios. Each node in a doubly linked list contains:
data, the value stored in the node.next, a pointer to the next node in the list.prev, a pointer to the previous node in the list.
The list itself maintains:
head, the head of the list, used for traversal from the start.tail, the tail of the list, used for traversal from the end and fast additions.len, the length of the list, tracking the number of nodes.
Operations that can be performed on doubly linked lists include:
- Insertion at the end O(1), based on the
tailpointer. - Insertion at arbitrary positions O(n), due to traversal requirements.
- Deletion O(n), with improved efficiency compared to singly linked lists it could easily find and remove nodes in this list without a full traversal.
const std = @import("std");
const Allocator = std.mem.Allocator;
fn DoublyLinkedList(comptime T: type) type {
return struct {
const Node = struct {
data: T,
next: ?*Node = null,
prev: ?*Node = null,
};
const Self = @This();
head: ?*Node = null,
tail: ?*Node = null,
len: usize = 0,
allocator: Allocator,
fn init(allocator: Allocator) Self {
return .{ .allocator = allocator };
}
// This function is equals to self.insertAt(self.len, value)
// But this cost O(1), while insertAt cost O(n) .
fn insertLast(self: *Self, value: T) !void {
const node = try self.allocator.create(Node);
node.* = Node{ .data = value, .prev = self.tail };
if (self.tail) |tail| {
tail.*.next = node;
} else {
self.head = node;
}
self.tail = node;
self.len += 1;
}
fn insertAt(self: *Self, position: usize, value: T) !void {
if (position > self.len) {
return error.OutOfRange;
}
defer self.len += 1;
const node = try self.allocator.create(Node);
node.* = Node{ .data = value };
var current = self.head;
// Find the node which is specified by the position
for (0..position) |_| {
if (current) |cur| {
current = cur.next;
}
}
// Put node in front of current
node.next = current;
if (current) |cur| {
node.*.prev = cur.prev;
if (cur.prev) |*prev| {
prev.*.next = node;
} else {
// When current has no prev, we are insert at head.
self.head = node;
}
cur.*.prev = node;
} else { // We are insert at tail, update node to new tail.
if (self.tail) |tail| {
node.*.prev = tail;
tail.*.next = node;
}
self.tail = node;
// Head may also be null for an empty list
if (null == self.head) {
self.head = node;
}
}
}
fn remove(self: *Self, value: T) bool {
var current = self.head;
while (current) |cur| : (current = cur.next) {
if (cur.data == value) {
// if the current node has a previous node
// then set the previous node's next to the current node's next
if (cur.prev) |prev| {
prev.next = cur.next;
} else {
// if the current node has no previous node
self.head = cur.next;
}
// if the current node has a next node
// then set the next node's previous to the current node's previous
if (cur.next) |next| {
next.prev = cur.prev;
} else {
// if the current node has no next node
// then set the tail to the current node's previous
self.tail = cur.prev;
}
self.allocator.destroy(cur);
self.len -= 1;
return true;
}
}
return false;
}
fn search(self: *Self, value: T) bool {
var current: ?*Node = self.head;
while (current) |cur| : (current = cur.next) {
if (cur.data == value) {
return true;
}
}
return false;
}
fn visit(self: Self, visitor: *const fn (i: usize, v: T) anyerror!void) !usize {
var current: ?*Node = self.head;
var i: usize = 0;
while (current) |cur| : (i += 1) {
try visitor(i, cur.data);
current = cur.next;
}
return i;
}
fn visitBackwards(self: Self, visitor: *const fn (i: usize, v: T) anyerror!void) !usize {
var current = self.tail;
var i: usize = 0;
while (current) |cur| : (i += 1) {
try visitor(i, cur.data);
current = cur.prev;
}
return i;
}
fn deinit(self: *Self) void {
var current = self.head;
while (current) |cur| {
const next = cur.next;
self.allocator.destroy(cur);
current = next;
}
self.head = null;
self.tail = null;
self.len = 0;
}
};
}
fn ensureList(lst: DoublyLinkedList(u32), comptime expected: []const u32) !void {
const visited_times = try lst.visit(struct {
fn visitor(i: usize, v: u32) !void {
if (expected.len == 0) {
unreachable;
} else {
try std.testing.expectEqual(v, expected[i]);
}
}
}.visitor);
try std.testing.expectEqual(visited_times, expected.len);
const visited_times2 = try lst.visitBackwards(struct {
fn visitor(i: usize, v: u32) !void {
if (expected.len == 0) {
unreachable;
} else {
try std.testing.expectEqual(v, expected[expected.len - i - 1]);
}
}
}.visitor);
try std.testing.expectEqual(visited_times2, expected.len);
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var list = DoublyLinkedList(u32).init(allocator);
defer list.deinit();
const values = [_]u32{ 1, 2, 3, 4, 5 };
for (values) |value| {
try list.insertLast(value);
}
try ensureList(list, &values);
try list.insertAt(1, 100);
try ensureList(list, &[_]u32{ 1, 100, 2, 3, 4, 5 });
try list.insertAt(0, 200);
try ensureList(list, &[_]u32{ 200, 1, 100, 2, 3, 4, 5 });
try std.testing.expect(list.remove(100));
try ensureList(list, &[_]u32{ 200, 1, 2, 3, 4, 5 });
// delete all
for (values) |value| {
try std.testing.expect(list.remove(value));
}
try std.testing.expect(list.remove(200));
try ensureList(list, &[_]u32{});
}
Argument Parsing
Parsing arguments is common in command line programs and there are some packages in Zig to make this task easier. To name a few:
Here we will give an example using simargs.
const std = @import("std");
const print = std.debug.print;
const simargs = @import("simargs");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
var opt = try simargs.parse(allocator, struct {
// Those fields declare arguments options
// only `output` is required, others are all optional
verbose: ?bool,
@"user-agent": enum { Chrome, Firefox, Safari } = .Firefox,
timeout: ?u16 = 30, // default value
output: []const u8 = "/tmp",
help: bool = false,
// This declares option's short name
pub const __shorts__ = .{
.verbose = .v,
.output = .o,
.@"user-agent" = .A,
.help = .h,
};
// This declares option's help message
pub const __messages__ = .{
.verbose = "Make the operation more talkative",
.output = "Write to file instead of stdout",
.timeout = "Max time this request can cost",
};
}, "[file]", null);
defer opt.deinit();
const sep = "-" ** 30;
print("{s}Program{s}\n{s}\n\n", .{ sep, sep, opt.program });
print("{s}Arguments{s}\n", .{ sep, sep });
inline for (std.meta.fields(@TypeOf(opt.args))) |fld| {
const format = "{s:>10}: " ++ switch (fld.type) {
[]const u8 => "{s}",
?[]const u8 => "{?s}",
else => "{any}",
} ++ "\n";
print(format, .{ fld.name, @field(opt.args, fld.name) });
}
print("\n{s}Positionals{s}\n", .{ sep, sep });
for (opt.positional_args, 0..) |arg, idx| {
print("{d}: {s}\n", .{ idx + 1, arg });
}
// Provide a print_help util method
print("\n{s}print_help{s}\n", .{ sep, sep });
const stdout = std.io.getStdOut();
try opt.printHelp(stdout.writer());
}
Database
This section will demonstrate how to connect to popular databases from Zig.
Data model used is as follows:
- Create two tables:
cat_colors,cats,catshas a reference incat_colors. - Create a prepare statement for each table, and insert data.
- Execute a join query to get
cat_nameandcolor_nameat the same time.
cat_colors
| id | name |
|---|---|
| 1 | Blue |
| 2 | Black |
cats
| id | name | color_id |
|---|---|---|
| 1 | Tigger | 1 |
| 2 | Sammy | 1 |
| 3 | Oreo | 2 |
| 4 | Biscuit | 2 |
SQLite
Although there are some wrapper package options for SQLite in Zig, they are unstable. So here we will introduce the C API interface.
Data models are introduced here.
/// SQLite API demo
/// https://www.sqlite.org/cintro.html
///
const std = @import("std");
const c = @cImport({
@cInclude("sqlite3.h");
});
const print = std.debug.print;
const DB = struct {
db: *c.sqlite3,
fn init(db: *c.sqlite3) DB {
return .{ .db = db };
}
fn deinit(self: DB) void {
_ = c.sqlite3_close(self.db);
}
fn execute(self: DB, query: [:0]const u8) !void {
var errmsg: [*c]u8 = undefined;
if (c.SQLITE_OK != c.sqlite3_exec(self.db, query, null, null, &errmsg)) {
defer c.sqlite3_free(errmsg);
print("Exec query failed: {s}\n", .{errmsg});
return error.execError;
}
return;
}
fn queryTable(self: DB) !void {
const stmt = blk: {
var stmt: ?*c.sqlite3_stmt = undefined;
const query =
\\ SELECT
\\ c.name,
\\ cc.name
\\ FROM
\\ cats c
\\ INNER JOIN cat_colors cc ON cc.id = c.color_id;
\\
;
if (c.SQLITE_OK != c.sqlite3_prepare_v2(self.db, query, query.len + 1, &stmt, null)) {
print("Can't create prepare statement: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.prepareStmt;
}
break :blk stmt.?;
};
defer _ = c.sqlite3_finalize(stmt);
var rc = c.sqlite3_step(stmt);
while (rc == c.SQLITE_ROW) {
// iCol is 0-based.
// Those return text are invalidated when call step, reset, finalize are called
// https://www.sqlite.org/c3ref/column_blob.html
const cat_name = c.sqlite3_column_text(stmt, 0);
const color_name = c.sqlite3_column_text(stmt, 1);
print("Cat {s} is in {s} color\n", .{ cat_name, color_name });
rc = c.sqlite3_step(stmt);
}
if (rc != c.SQLITE_DONE) {
print("Step query failed: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.stepQuery;
}
}
fn insertTable(self: DB) !void {
const insert_color_stmt = blk: {
var stmt: ?*c.sqlite3_stmt = undefined;
const query = "INSERT INTO cat_colors (name) values (?1)";
if (c.SQLITE_OK != c.sqlite3_prepare_v2(self.db, query, query.len + 1, &stmt, null)) {
print("Can't create prepare statement: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.prepareStmt;
}
break :blk stmt.?;
};
defer _ = c.sqlite3_finalize(insert_color_stmt);
const insert_cat_stmt = blk: {
var stmt: ?*c.sqlite3_stmt = undefined;
const query = "INSERT INTO cats (name, color_id) values (?1, ?2)";
if (c.SQLITE_OK != c.sqlite3_prepare_v2(self.db, query, query.len + 1, &stmt, null)) {
print("Can't create prepare statement: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.prepareStmt;
}
break :blk stmt.?;
};
defer _ = c.sqlite3_finalize(insert_cat_stmt);
const cat_colors = .{
.{
"Blue", .{
"Tigger",
"Sammy",
},
},
.{
"Black", .{
"Oreo",
"Biscuit",
},
},
};
inline for (cat_colors) |row| {
const color = row.@"0";
const cat_names = row.@"1";
// bind index is 1-based.
if (c.SQLITE_OK != c.sqlite3_bind_text(insert_color_stmt, 1, color, color.len, c.SQLITE_STATIC)) {
print("Can't bind text: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.bindText;
}
if (c.SQLITE_DONE != c.sqlite3_step(insert_color_stmt)) {
print("Can't step color stmt: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.step;
}
_ = c.sqlite3_reset(insert_color_stmt);
const last_id = c.sqlite3_last_insert_rowid(self.db);
inline for (cat_names) |cat_name| {
if (c.SQLITE_OK != c.sqlite3_bind_text(insert_cat_stmt, 1, cat_name, cat_name.len, c.SQLITE_STATIC)) {
print("Can't bind cat name: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.bindText;
}
if (c.SQLITE_OK != c.sqlite3_bind_int64(insert_cat_stmt, 2, last_id)) {
print("Can't bind cat color_id: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.bindText;
}
if (c.SQLITE_DONE != c.sqlite3_step(insert_cat_stmt)) {
print("Can't step cat stmt: {s}\n", .{c.sqlite3_errmsg(self.db)});
return error.step;
}
_ = c.sqlite3_reset(insert_cat_stmt);
}
}
return;
}
};
pub fn main() !void {
const version = c.sqlite3_libversion();
print("libsqlite3 version is {s}\n", .{version});
var c_db: ?*c.sqlite3 = undefined;
if (c.SQLITE_OK != c.sqlite3_open(":memory:", &c_db)) {
print("Can't open database: {s}\n", .{c.sqlite3_errmsg(c_db)});
return;
}
const db = DB.init(c_db.?);
defer db.deinit();
try db.execute(
\\ create table if not exists cat_colors (
\\ id integer primary key,
\\ name text not null unique
\\ );
\\ create table if not exists cats (
\\ id integer primary key,
\\ name text not null,
\\ color_id integer not null references cat_colors(id)
\\ );
);
try db.insertTable();
try db.queryTable();
}
Postgres
As with previous section, here we introduce libpq interface directly, other than wrapper package.
Data models used in this demo are the same with the one used in SQLite section.
Note: After executing a query with
PQexeclike functions, if there are returning results, check the result withPGRES_TUPLES_OK, otherwisePGRES_COMMAND_OKshould be used.
//! Libpq API example
//! https://gist.github.com/jiacai2050/00709b98ee69d73d022d2f293555f08f
//! https://www.postgresql.org/docs/16/libpq-example.html
//!
const std = @import("std");
const print = std.debug.print;
const c = @cImport({
@cInclude("libpq-fe.h");
});
const DB = struct {
conn: *c.PGconn,
fn init(conn_info: [:0]const u8) !DB {
const conn = c.PQconnectdb(conn_info);
if (c.PQstatus(conn) != c.CONNECTION_OK) {
print("Connect failed, err: {s}\n", .{c.PQerrorMessage(conn)});
return error.connect;
}
return DB{ .conn = conn.? };
}
fn deinit(self: DB) void {
c.PQfinish(self.conn);
}
// Execute a query without returning any data.
fn exec(self: DB, query: [:0]const u8) !void {
const result = c.PQexec(self.conn, query);
defer c.PQclear(result);
if (c.PQresultStatus(result) != c.PGRES_COMMAND_OK) {
print("exec query failed, query:{s}, err: {s}\n", .{ query, c.PQerrorMessage(self.conn) });
return error.Exec;
}
}
fn insertTable(self: DB) !void {
// 1. create two prepared statements.
{
// There is no `get_last_insert_rowid` in libpq, so we use RETURNING id to get the last insert id.
const res = c.PQprepare(
self.conn,
"insert_cat_colors",
"INSERT INTO cat_colors (name) VALUES ($1) returning id",
1, // nParams, number of parameters supplied
// Specifies, by OID, the data types to be assigned to the parameter symbols.
// When null, the server infers a data type for the parameter symbol in the same way it would do for an untyped literal string.
null, // paramTypes.
);
defer c.PQclear(res);
if (c.PQresultStatus(res) != c.PGRES_COMMAND_OK) {
print("prepare insert cat_colors failed, err: {s}\n", .{c.PQerrorMessage(self.conn)});
return error.prepare;
}
}
{
const res = c.PQprepare(self.conn, "insert_cats", "INSERT INTO cats (name, color_id) VALUES ($1, $2)", 2, null);
defer c.PQclear(res);
if (c.PQresultStatus(res) != c.PGRES_COMMAND_OK) {
print("prepare insert cats failed, err: {s}\n", .{c.PQerrorMessage(self.conn)});
return error.prepare;
}
}
const cat_colors = .{
.{
"Blue", .{
"Tigger",
"Sammy",
},
},
.{
"Black", .{
"Oreo",
"Biscuit",
},
},
};
// 2. Use prepared statements to insert data.
inline for (cat_colors) |row| {
const color = row.@"0";
const cat_names = row.@"1";
const color_id = blk: {
const res = c.PQexecPrepared(
self.conn,
"insert_cat_colors",
1, // nParams
&[_][*c]const u8{color}, // paramValues
&[_]c_int{color.len}, // paramLengths
&[_]c_int{0}, // paramFormats
0, // resultFormat
);
defer c.PQclear(res);
// Since this insert has returns, so we check res with PGRES_TUPLES_OK
if (c.PQresultStatus(res) != c.PGRES_TUPLES_OK) {
print("exec insert cat_colors failed, err: {s}\n", .{c.PQresultErrorMessage(res)});
return error.InsertCatColors;
}
break :blk std.mem.span(c.PQgetvalue(res, 0, 0));
};
inline for (cat_names) |name| {
const res = c.PQexecPrepared(
self.conn,
"insert_cats",
2, // nParams
&[_][*c]const u8{ name, color_id }, // paramValues
&[_]c_int{ name.len, @intCast(color_id.len) }, // paramLengths
&[_]c_int{ 0, 0 }, // paramFormats
0, // resultFormat, 0 means text, 1 means binary.
);
defer c.PQclear(res);
// This insert has no returns, so we check res with PGRES_COMMAND_OK
if (c.PQresultStatus(res) != c.PGRES_COMMAND_OK) {
print("exec insert cats failed, err: {s}\n", .{c.PQresultErrorMessage(res)});
return error.InsertCats;
}
}
}
}
fn queryTable(self: DB) !void {
const query =
\\ SELECT
\\ c.name,
\\ cc.name
\\ FROM
\\ cats c
\\ INNER JOIN cat_colors cc ON cc.id = c.color_id;
\\
;
const result = c.PQexec(self.conn, query);
defer c.PQclear(result);
if (c.PQresultStatus(result) != c.PGRES_TUPLES_OK) {
print("exec query failed, query:{s}, err: {s}\n", .{ query, c.PQerrorMessage(self.conn) });
return error.queryTable;
}
const num_rows = c.PQntuples(result);
for (0..@intCast(num_rows)) |row| {
const cat_name = std.mem.span(c.PQgetvalue(result, @intCast(row), 0));
const color_name = std.mem.span(c.PQgetvalue(result, @intCast(row), 1));
print("Cat {s} is in {s} color\n", .{ cat_name, color_name });
}
}
};
pub fn main() !void {
const conn_info = "host=127.0.0.1 user=postgres password=postgres dbname=postgres";
const db = try DB.init(conn_info);
defer db.deinit();
try db.exec(
\\ create table if not exists cat_colors (
\\ id integer primary key generated always as identity,
\\ name text not null unique
\\ );
\\ create table if not exists cats (
\\ id integer primary key generated always as identity,
\\ name text not null,
\\ color_id integer not null references cat_colors(id)
\\ );
);
try db.insertTable();
try db.queryTable();
}
MySQL
As with sqlite section, here we introduce libmysqlclient interface directly.
Data models are introduced here.
Note: After executing a query with
mysql_real_querylike functions, if there are returning results, we must consume the result, otherwise we will get following error when we execute next query.
Commands out of sync; you can't run this command now
//! MySQL 8.0 API demo
//! https://dev.mysql.com/doc/c-api/8.0/en/c-api-basic-interface-usage.html
//!
const std = @import("std");
const Allocator = std.mem.Allocator;
const c = @cImport({
@cInclude("mysql.h");
});
const print = std.debug.print;
pub const DBInfo = struct {
host: [:0]const u8,
user: [:0]const u8,
password: [:0]const u8,
database: [:0]const u8,
port: u32 = 3306,
};
pub const DB = struct {
conn: *c.MYSQL,
allocator: Allocator,
fn init(allocator: Allocator, db_info: DBInfo) !DB {
const db = c.mysql_init(null);
if (db == null) {
return error.initError;
}
if (c.mysql_real_connect(
db,
db_info.host,
db_info.user,
db_info.password,
db_info.database,
db_info.port,
null,
c.CLIENT_MULTI_STATEMENTS,
) == null) {
print("Connect to database failed: {s}\n", .{c.mysql_error(db)});
return error.connectError;
}
return .{
.conn = db,
.allocator = allocator,
};
}
fn deinit(self: DB) void {
c.mysql_close(self.conn);
}
fn execute(self: DB, query: []const u8) !void {
if (c.mysql_real_query(self.conn, query.ptr, query.len) != 0) {
print("Exec query failed: {s}\n", .{c.mysql_error(self.conn)});
return error.execError;
}
}
fn queryTable(self: DB) !void {
const query =
\\ SELECT
\\ c.name,
\\ cc.name
\\ FROM
\\ cats c
\\ INNER JOIN cat_colors cc ON cc.id = c.color_id;
\\
;
try self.execute(query);
const result = c.mysql_store_result(self.conn);
if (result == null) {
print("Store result failed: {s}\n", .{c.mysql_error(self.conn)});
return error.storeResultError;
}
defer c.mysql_free_result(result);
while (c.mysql_fetch_row(result)) |row| {
const cat_name = row[0];
const color_name = row[1];
print("Cat: {s}, Color: {s}\n", .{ cat_name, color_name });
}
}
fn insertTable(self: DB) !void {
const cat_colors = .{
.{
"Blue",
.{ "Tigger", "Sammy" },
},
.{
"Black",
.{ "Oreo", "Biscuit" },
},
};
const insert_color_stmt: *c.MYSQL_STMT = blk: {
const stmt = c.mysql_stmt_init(self.conn);
if (stmt == null) {
return error.initStmt;
}
errdefer _ = c.mysql_stmt_close(stmt);
const insert_color_query = "INSERT INTO cat_colors (name) values (?)";
if (c.mysql_stmt_prepare(stmt, insert_color_query, insert_color_query.len) != 0) {
print("Prepare color stmt failed, msg:{s}\n", .{c.mysql_error(self.conn)});
return error.prepareStmt;
}
break :blk stmt.?;
};
defer _ = c.mysql_stmt_close(insert_color_stmt);
const insert_cat_stmt = blk: {
const stmt = c.mysql_stmt_init(self.conn);
if (stmt == null) {
return error.initStmt;
}
errdefer _ = c.mysql_stmt_close(stmt);
const insert_cat_query = "INSERT INTO cats (name, color_id) values (?, ?)";
if (c.mysql_stmt_prepare(stmt, insert_cat_query, insert_cat_query.len) != 0) {
print("Prepare cat stmt failed: {s}\n", .{c.mysql_error(self.conn)});
return error.prepareStmt;
}
break :blk stmt.?;
};
defer _ = c.mysql_stmt_close(insert_cat_stmt);
inline for (cat_colors) |row| {
const color = row.@"0";
const cat_names = row.@"1";
var color_binds = [_]c.MYSQL_BIND{std.mem.zeroes(c.MYSQL_BIND)};
color_binds[0].buffer_type = c.MYSQL_TYPE_STRING;
color_binds[0].buffer_length = color.len;
color_binds[0].is_null = 0;
color_binds[0].buffer = @constCast(@ptrCast(color.ptr));
if (c.mysql_stmt_bind_param(insert_color_stmt, &color_binds)) {
print("Bind color param failed: {s}\n", .{c.mysql_error(self.conn)});
return error.bindParamError;
}
if (c.mysql_stmt_execute(insert_color_stmt) != 0) {
print("Exec color stmt failed: {s}\n", .{c.mysql_error(self.conn)});
return error.execStmtError;
}
const last_id = c.mysql_stmt_insert_id(insert_color_stmt);
_ = c.mysql_stmt_reset(insert_color_stmt);
inline for (cat_names) |cat_name| {
var cat_binds = [_]c.MYSQL_BIND{ std.mem.zeroes(c.MYSQL_BIND), std.mem.zeroes(c.MYSQL_BIND) };
cat_binds[0].buffer_type = c.MYSQL_TYPE_STRING;
cat_binds[0].buffer_length = cat_name.len;
cat_binds[0].buffer = @constCast(@ptrCast(cat_name.ptr));
cat_binds[1].buffer_type = c.MYSQL_TYPE_LONG;
cat_binds[1].length = (@as(c_ulong, 1));
cat_binds[1].buffer = @constCast(@ptrCast(&last_id));
if (c.mysql_stmt_bind_param(insert_cat_stmt, &cat_binds)) {
print("Bind cat param failed: {s}\n", .{c.mysql_error(self.conn)});
return error.bindParamError;
}
if (c.mysql_stmt_execute(insert_cat_stmt) != 0) {
print("Exec cat stmt failed: {s}\n", .{c.mysql_error(self.conn)});
return error.execStmtError;
}
_ = c.mysql_stmt_reset(insert_cat_stmt);
}
}
}
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
const version = c.mysql_get_client_version();
print("MySQL client version is {}\n", .{version});
const db = try DB.init(allocator, .{
.database = "public",
.host = "127.0.0.1",
.user = "root",
.password = "root",
});
defer db.deinit();
try db.execute(
\\ CREATE TABLE IF NOT EXISTS cat_colors (
\\ id INT AUTO_INCREMENT PRIMARY KEY,
\\ name VARCHAR(255) NOT NULL
\\);
\\
\\CREATE TABLE IF NOT EXISTS cats (
\\ id INT AUTO_INCREMENT PRIMARY KEY,
\\ name VARCHAR(255) NOT NULL,
\\ color_id INT NOT NULL
\\)
);
// Since we use multi-statement, we need to consume all results.
// Otherwise we will get following error when we execute next query.
// Commands out of sync; you can't run this command now
//
// https://dev.mysql.com/doc/c-api/8.0/en/mysql-next-result.html
while (c.mysql_next_result(db.conn) == 0) {
const res = c.mysql_store_result(db.conn);
c.mysql_free_result(res);
}
try db.insertTable();
try db.queryTable();
}
Regular Expressions
Currently there is no regex support in Zig, so the best way to go is binding with Posix's regex.h.
Interop with C is easy in Zig, but since translate-c doesn't support bitfields, we can't use regex_t directly. So here we create a static C library first, providing two functions:
regex_t* alloc_regex_t(void);
void free_regex_t(regex_t* ptr);
regex_t* is a pointer, it has fixed size, so we can use it directly in Zig.
const std = @import("std");
const print = std.debug.print;
const c = @cImport({
@cInclude("regex.h");
// This is our static library.
@cInclude("regex_slim.h");
});
const Regex = struct {
inner: *c.regex_t,
fn init(pattern: [:0]const u8) !Regex {
const inner = c.alloc_regex_t().?;
if (0 != c.regcomp(inner, pattern, c.REG_NEWLINE | c.REG_EXTENDED)) {
return error.compile;
}
return .{
.inner = inner,
};
}
fn deinit(self: Regex) void {
c.free_regex_t(self.inner);
}
fn matches(self: Regex, input: [:0]const u8) bool {
const match_size = 1;
var pmatch: [match_size]c.regmatch_t = undefined;
return 0 == c.regexec(self.inner, input, match_size, &pmatch, 0);
}
fn exec(self: Regex, input: [:0]const u8) !void {
const match_size = 1;
var pmatch: [match_size]c.regmatch_t = undefined;
var i: usize = 0;
var string = input;
const expected = [_][]const u8{ "John Do", "John Foo" };
while (true) {
if (0 != c.regexec(self.inner, string, match_size, &pmatch, 0)) {
break;
}
const slice = string[@as(usize, @intCast(pmatch[0].rm_so))..@as(usize, @intCast(pmatch[0].rm_eo))];
try std.testing.expectEqualStrings(expected[i], slice);
string = string[@intCast(pmatch[0].rm_eo)..];
i += 1;
}
try std.testing.expectEqual(i, 2);
}
};
pub fn main() !void {
{
const regex = try Regex.init("[ab]c");
defer regex.deinit();
try std.testing.expect(regex.matches("bc"));
try std.testing.expect(!regex.matches("cc"));
}
{
const regex = try Regex.init("John.*o");
defer regex.deinit();
try regex.exec(
\\ 1) John Driverhacker;
\\ 2) John Doe;
\\ 3) John Foo;
\\
);
}
}
References
- regex(3) — Linux manual page
- How to allocate a struct of incomplete type in Zig?
- Regular Expressions in Zig
String Parsing
String to number/enum
const std = @import("std");
const expectEqual = std.testing.expectEqual;
const expectError = std.testing.expectError;
const parseInt = std.fmt.parseInt;
const parseFloat = std.fmt.parseFloat;
const stringToEnum = std.meta.stringToEnum;
pub fn main() !void {
try expectEqual(parseInt(i32, "123", 10), 123);
try expectEqual(parseInt(i32, "-123", 10), -123);
try expectError(error.Overflow, parseInt(u4, "123", 10));
// 0 means auto detect the base.
// base = 16
try expectEqual(parseInt(i32, "0xF", 0), 15);
// base = 2
try expectEqual(parseInt(i32, "0b1111", 0), 15);
// base = 8
try expectEqual(parseInt(i32, "0o17", 0), 15);
try expectEqual(parseFloat(f32, "1.23"), 1.23);
try expectEqual(parseFloat(f32, "-1.23"), -1.23);
const Color = enum {
Red,
Blue,
Green,
};
try expectEqual(stringToEnum(Color, "Red").?, Color.Red);
try expectEqual(stringToEnum(Color, "Yello"), null);
}